qdrant collection 생성
n8n 공식 기술 문서 한글판 by 인포그랩
인포그랩에서 OpenAI 기술 기반으로 자체 개발한 자동화 번역 프로그램을 통해 n8n 공식 문서의 한글판을 국내 최초로 제공합니다.
n8n-docs.infograb.net
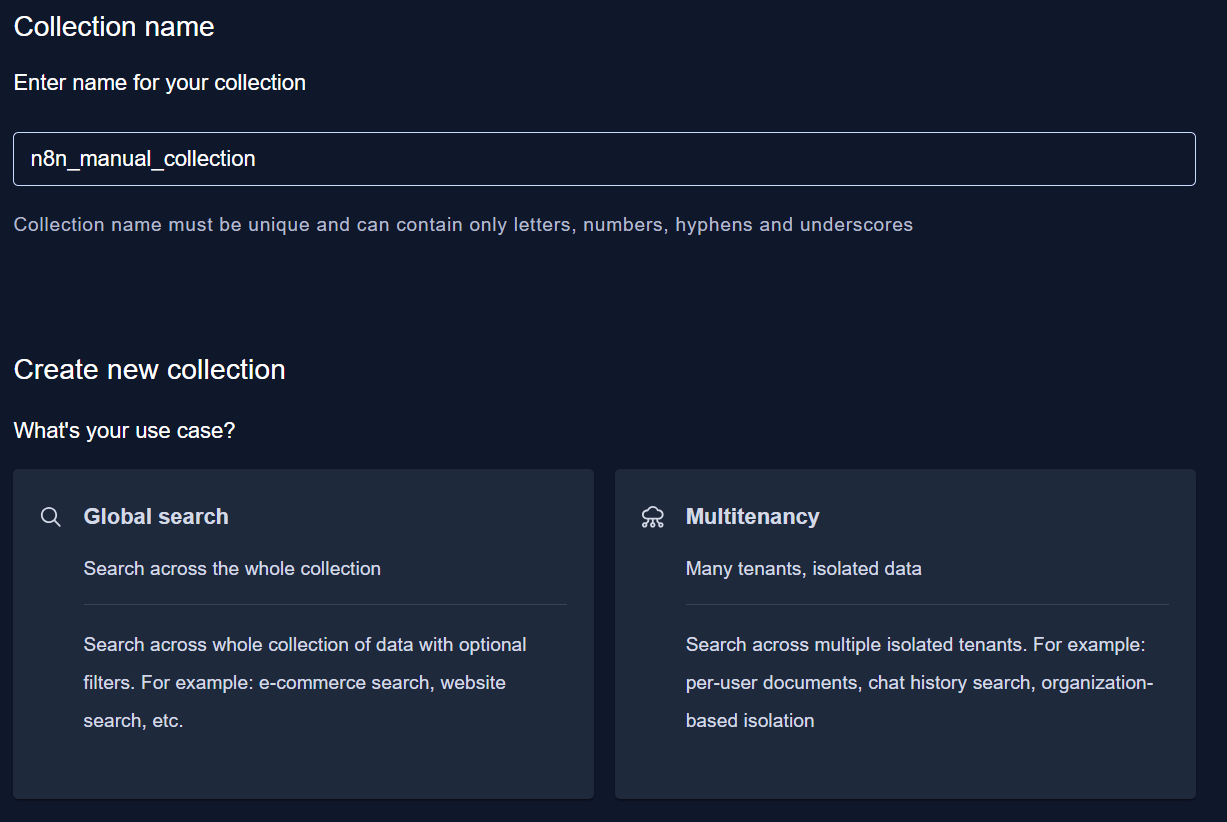
이건 **컬렉션의 사용 목적(use case)**을 정의하는 항목이에요:
| 🔍 Global search | 전체 컬렉션 대상 검색 | ✅ 적합 |
| 🏢 Multitenancy | 사용자별 격리된 데이터 저장 | ❌ (n8n 매뉴얼엔 불필요) |
👉 Global search 선택하면 됩니다.
n8n 매뉴얼은 특정 사용자나 조직 단위로 분리할 필요가 없기 때문이에요.

컬렉션 생성 시 검색 방식(Search configuration) 을 고르는 단계입니다.
🔍 옵션 설명
| 옵션 | 설명 | 추천여부 |
| ✅ Simple Single embedding | 가장 기본적인 방식. 문서당 벡터 1개만 저장됨 | 👍 기본용으로 매우 적합 |
| ✅ Simple Hybrid Search | Dense + Sparse 벡터를 동시에 저장/검색 → 키워드 검색과 의미 기반 검색 동시 가능 | 🔥 고급 챗봇이나 FAQ 추천에 적합 |
| ⚙️ Custom | 필드, 벡터, 필터 조건 등 전부 수동 설정 | ❌ 초심자/빠른 구축에는 비추천 (복잡) |
📌 n8n 매뉴얼용이라면?
📘 단순 매뉴얼 검색이라면 →
✅ Simple Single embedding 추천
💬 검색 품질(키워드+의미)도 중요하다면 →
✅ Simple Hybrid Search 도 매우 좋음 (다만 embedding 과정이 더 복잡)
✨ 선택 가이드
| 그냥 n8n에 문서 넣고 질문/답변 하고 싶다 | ✅ Simple Single embedding |
| 키워드 + 의미 기반 복합 검색 하고 싶다 | ✅ Simple Hybrid Search |
| embedding 모델 여러 개 쓸 예정이거나, 벡터 필드가 2개 이상 | Custom (고급 사용자용) |
🧠 n8n에서 연동할 때도
- 대부분 LangChain + OpenAI(OpenEmbedding) 기반이면 → Simple Single embedding으로 충분합니다.
- 만약 Hybrid Search 쓰려면 sparse_vector까지 지원하는 embedding 모델(OpenAI + Cohere 등)을 고려해야 합니다.
요약 먼저: 추천 선택
매뉴얼 챗봇 용도라면 → Simple Hybrid Search 가 가장 적합합니다.
📌 각 옵션 비교 (챗봇 기준)
| 🔹 Simple Single embedding | 단일 벡터 필드, 의미 기반 검색만 | ⚠️ 기본 수준 | 키워드 검색 불가, 질문 표현 조금만 달라도 못 찾는 경우 발생 |
| 🔸 Simple Hybrid Search | Dense + Sparse (의미 + 키워드) 병합 검색 | ✅ 매우 적합 | 의미 기반 + 키워드 기반 질문 모두 커버 가능 (ex: “삭제 방법” vs “remove”) |
| ⚙️ Custom | 완전 수동 설정 | ❌ 복잡도↑ | 추상화된 필드나 다중 embedding이 필요한 특수 상황만 해당됨 |
🎯 왜 Hybrid Search가 좋은가?
실제 사용자 질문은 다음처럼 나뉩니다:
- 의미 기반 질문:
"문서 삭제는 어떻게 해?"
"파일 제거 방법 알려줘" - 키워드 기반 질문:
"delete function"
"manual에서 remove 항목"
✅ Simple Hybrid Search는 둘 다 매칭이 가능
❌ Single embedding은 dense vector만 쓰기 때문에 "remove"와 "삭제"를 연결 못 할 수도 있음
📚 적용 팁 (n8n + Qdrant)
- Hybrid Search를 쓰면 Qdrant에 Dense + Sparse 벡터 필드가 함께 저장됩니다
- OpenAI embedding + BM25 기반 sparse 생성기를 함께 써야 합니다
- n8n에서 넣을 때도 LangChain으로 HybridEmbedding 혹은 metadata 필드에 sparse 포함되도록 구성 가능
✅ 최종 정리
| 매뉴얼 기반 챗봇인가요? | ✅ 예 |
| 사용자 질문이 자유로운가요? | ✅ 예 |
| 키워드 기반 검색도 지원하고 싶은가요? | ✅ 예 |
| → 결론 | Simple Hybrid Search 추천 |

이 화면은 Qdrant에서 Simple Hybrid Search 또는 Custom을 선택했을 때 나오는
Vector configuration 단계예요.
즉, Qdrant 컬렉션에 저장될 Dense + Sparse 벡터 필드의 이름, 차원 수, 거리 측정 방식 등을 수동으로 지정하는 화면입니다.
지금 이 설정은 왜 필요한가?
Hybrid Search는 두 가지 벡터 필드를 동시에 사용합니다:
| 🟦 Dense vector | 의미 기반 벡터 | embedding / dense_vector |
| 🟨 Sparse vector | 키워드 기반 벡터 (ex: BM25) | sparse_embedding / bm25_vector |
✍️ 필드별 설명
Dense vector name
- 벡터 필드 이름. 예: dense_vector or embedding
- n8n/LangChain 등에서 임베딩 결과를 이 필드에 매핑해야 함
- OpenAI, Cohere, Azure 등 임베딩 모델에서 나오는 dense vector
Dimensions
- 벡터 차원 (예: OpenAI text-embedding-3-small은 1536차원)
- Qdrant는 정확히 맞는 차원 수가 아니면 저장 불가
- OpenAI 쓰면 보통: 1536
Metric
- 벡터 거리 측정 방식 (유사도 계산 기준)
- 일반적으로 Cosine 사용 (추천)
- 다른 옵션: Dot, Euclidean
🔶 Sparse vector name (optional, Hybrid일 때만)
- BM25나 keyword 기반 sparse 벡터를 저장할 필드 이름
- 예: sparse_vector, bm25_vector, keyword_embedding
🧠 Use IDF?
- Inverse Document Frequency 적용 여부 (정보 검색에서 자주 등장)
- BM25 등의 sparse 모델 사용할 때 체크함
- 대부분의 hybrid embedding 라이브러리(CoHere RAG 등)에서는 체크함
✅ 예시 값 (OpenAI + BM25 Hybrid)
| Dense vector name | dense_vector |
| Dimensions | 1536 |
| Metric | Cosine |
| Sparse vector name | sparse_vector |
| Use IDF | ✅ (체크) |
🧠 만약 n8n에서 연동하려면?
- LangChain에서 QdrantVectorStore 생성 시 아래처럼 매핑해야 해요:
new QdrantVectorStore(embeddings, {
collectionName: 'n8n_manual_collection',
vectorName: 'dense_vector',
sparseVectorName: 'sparse_vector'
});
✅ 최종 정리
Dense는 의미 기반, Sparse는 키워드 기반
Hybrid Search를 쓸 거라면 둘 다 정의하고,
사용하는 embedding 모델에 따라 차원 수와 IDF 여부를 정확히 설정해야 합니다.

이 화면은 Qdrant 컬렉션 설정 중 Payload Indexes 설정 영역입니다.
이건 벡터 검색과는 별도로 **"payload(메타데이터)에 대해 필터링 검색을 하고 싶을 때 필요한 인덱스"**를 지정하는 기능이에요.
🔍 간단 정의
Payload Index = "벡터와 연결된 메타데이터 필드에 대해 필터링(search by field)을 하기 위한 인덱스"
✅ 왜 필요한가?
Qdrant에서는 벡터만으로 유사도 검색을 하지만,
**payload(문서의 메타정보: 파일명, 카테고리, 작성자 등)**를 기준으로 필터링 조건 검색도 가능해요.
하지만 그걸 빠르게 하려면 인덱스를 따로 만들어야 합니다.
🎯 예시 상황
| "카테고리가 'n8n'인 문서 중" | category 필드에 인덱스 필요 |
| "language가 'ko'인 문서만" | lang 필드에 인덱스 필요 |
| "source = 'manual' AND chunk_index < 5" | source, chunk_index 모두 인덱스 대상이 되어야 빠름 |
🛠️ 실전 구성 예시
당신이 upsert할 때 아래처럼 payload를 넣었다면:
{
"payload": {
"filename": "manual_001.txt",
"category": "n8n",
"lang": "ko"
}
}→ 필터링 조건 검색을 하려면 category, lang 에 대해 Payload Index를 등록해야 함
✍️ 설정 방법
이 화면에서 + Add 누르면:
| Field name | category |
| Type | keyword, integer, text, bool 등 |
Qdrant는 타입까지 지정해줘야 효율적으로 인덱싱하고 필터링할 수 있습니다.
✅ 요약 정리
| Payload Index | 메타데이터 필드로 필터 검색을 하려면 반드시 필요 |
| 언제 쓰나? | "lang = 'ko'", "category = 'faq'" 같은 필터 조건을 쓰고 싶을 때 |
| 안 쓰면? | 벡터 유사도 검색은 되지만, 필터링은 느리거나 불가능 |
qrant DB에서 metaData를 통해 필터 기능이 필요해짐
Payload indexes를 통해 필터기능을 사용해볼 것이다.

화면은 Qdrant 컬렉션에서 payload 필드를 인덱싱하는 설정
1. Field name
- 인덱스를 걸고 싶은 payload 키 이름.
- 여기서는 file_name이라고 해서, 벡터 삽입 시 payload에 들어가는 "file_name": "manual.pdf" 같은 값에 대해 검색 최적화를 하겠다는 뜻이야.
2. Field type
- 이 필드의 데이터 타입에 맞게 선택하는 옵션.
- 주요 타입:
- keyword: 단일 값, 토큰화 없이 완전 일치 검색. (ID, 코드, 짧은 라벨 등)
- text: 토큰화해서 full-text 검색, 부분 매칭 가능. (문장, 제목, 파일명 같이 문자열 검색)
- integer/float: 숫자 범위 검색.
- uuid/datetime/geo/bool: 각각 특수 타입.
- file_name은 보통 전체 문자열 매치로 쓰고 싶으니 keyword로 해도 되고, 부분 검색(예: manual이 포함된 파일)까지 하고 싶으면 text가 맞아.
3. Tokenizer
- text 타입일 때만 적용됨. 문자열을 토큰으로 나누는 방법.
- 옵션:
- whitespace: 공백 기준으로 쪼갬. "manual.pdf" → "manual.pdf" (사실상 단일 토큰)
- word: 단어 단위 분리.
- prefix: 접두어 단위 분리(자동 완성 기능 유사).
- 파일명은 사실 공백이 거의 없으니 whitespace 쓰면 파일명 전체가 하나의 토큰으로 들어가서 "equals"나 "match" 조건에 잘 맞아.
4. Lowercase
- 체크하면 모든 문자열을 소문자로 변환해서 저장.
- "Manual.PDF"와 "manual.pdf"를 같은 걸로 인식하게 해줌.
- 파일명 검색할 땐 웬만하면 켜두는 게 좋아.
5. Min / Max token length
- 토큰 필터링 옵션.
- 예: Min=3 → 세 글자 미만은 무시 (불용어, 짧은 토큰 제거).
- 파일명 같은 경우 대부분 긴 문자열이라 기본값(빈칸) 두는 게 무난.
✅ 정리
- file_name을 고유하게 관리하려면 사실 keyword 타입이 더 적합해 → 완전 일치 검색용.
- text + whitespace를 쓰면 부분 검색도 가능하지만, 파일 삭제 같은 정확 매칭 작업엔 굳이 필요 없음.
- file_id는 무조건 keyword 타입으로 만드는 게 좋아 (ID는 딱 떨어지는 값이니까).
👉 즉, 지금처럼 text + whitespace로 둬도 동작은 하지만, 삭제/필터 목적이라면 file_id → keyword, file_name → keyword로 해두는 게 가장 깔끔해.
타입 keyword(권장) 또는 text+lowercase 이게 무슨 차이?
Qdrant에서 Payload 인덱스 타입에 따라 검색/삭제 동작이 달라져. file_name 같은 필드라서 keyword vs text(lowercase)가 헷갈릴 수 있거든.
1. keyword
- 완전 일치 검색 전용
- "file_name": "manual.pdf" → equals "manual.pdf" 조건일 때만 매치.
- 토큰 분리 없음 (문자열 전체를 하나의 값으로 취급).
- 속도 빠르고, 삭제/업데이트 같은 “정확한 매칭”에 적합.
- 용도: 파일명, UUID, 코드, 카테고리 라벨 같은 고유 식별자.
2. text (+ lowercase 옵션)
- 토큰화(Text search) 기능. (설정한 tokenizer에 따라 단어, prefix, 공백 등으로 쪼갬)
- "manual.pdf" → "manual", "pdf" 등으로 나뉘어 저장될 수 있음.
- 검색 시 "manual"만 넣어도 매칭 가능 → 부분검색/풀텍스트검색에 유리.
- lowercase 옵션을 켜면 대소문자 구분 없이 검색됨.
- 용도: 문장, 설명, 제목, 태그처럼 부분 검색/풀텍스트 검색을 하고 싶을 때.
3. 차이 요약
타입 검색 방식 장점 단점 keyword 완전 일치만 빠르고 확실함 부분 검색 불가 text+lowercase 부분 검색/단어 검색 "manual"만 쳐도 "manual.pdf" 찾음 삭제 시 “manual”만 주면 의도치 않게 여러 개 지워질 수 있음
✅ 파일 삭제용으로는 keyword가 무조건 안전해.
- file_name = keyword → “manual.pdf”만 정확히 지움.
- file_name = text → “manual”로만 매치하면 "manual.pdf", "manual_guide.docx" 다 날아갈 수 있음.
👉 즉, 네 케이스처럼 “특정 파일만 지우기”가 목적이라면 keyword 타입을 추천해.
혹시 파일 검색(부분매칭)까지 쓰고 싶으면, file_name=keyword(삭제용) + file_name_search=text(검색용) 이렇게 필드를 따로 두는 방법도 있어.